Evaluation Charts
The table gives exact scores. The selected charts below provide visual evidence for sprint progression, guardrail behaviour, category performance, and latency.Sprint 3 Evidence
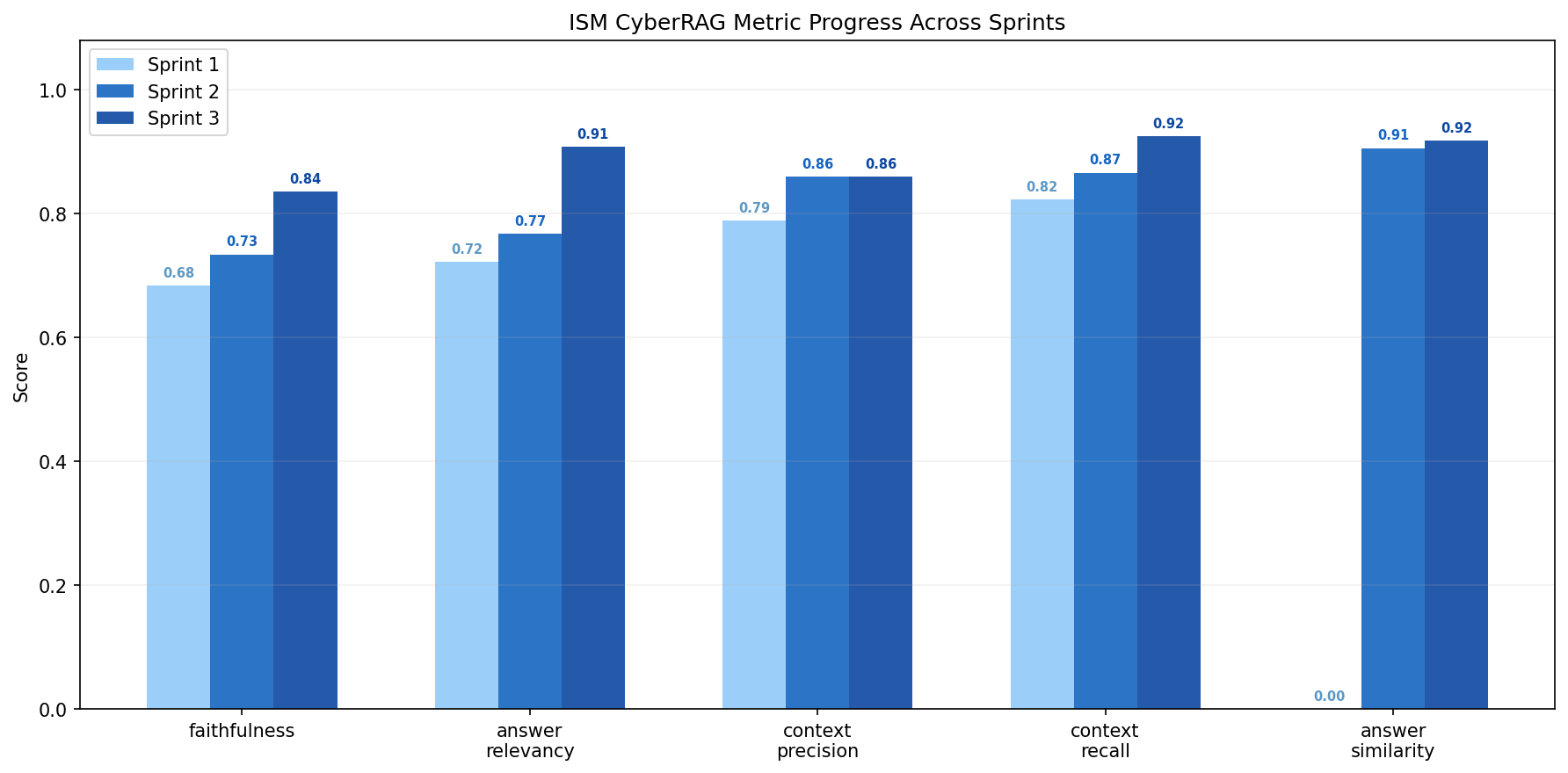
Sprint 1 vs Sprint 2 vs Sprint 3 Comparison
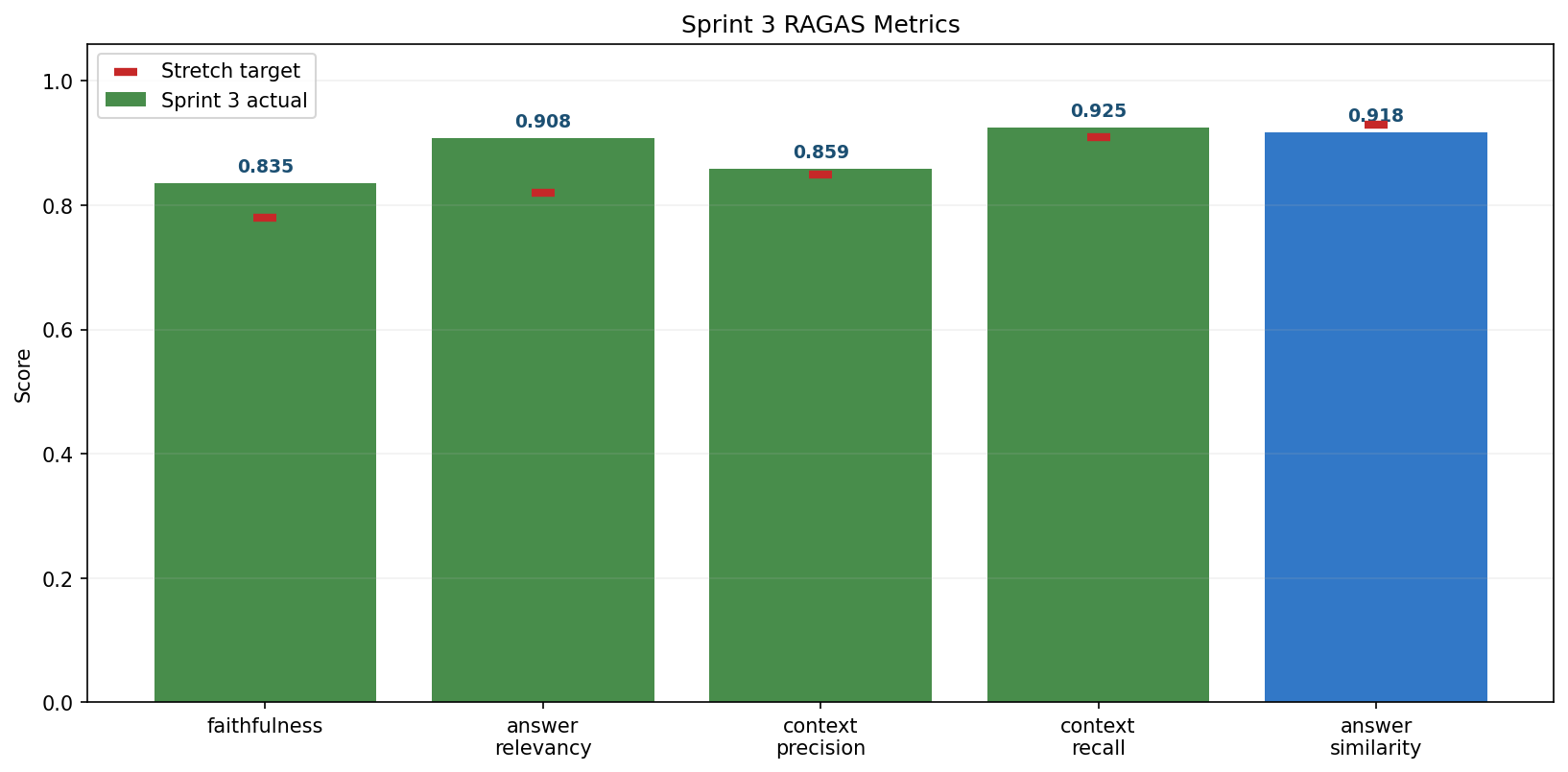
Sprint 3 RAGAS Metrics
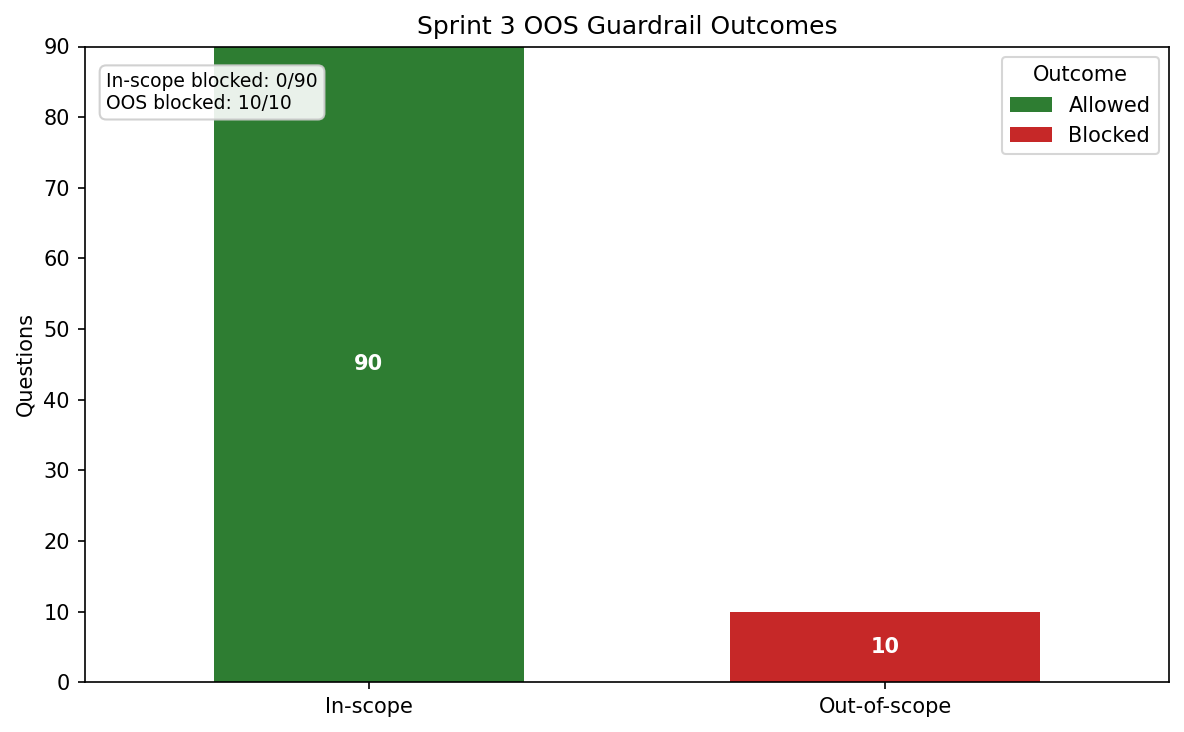
Guardrail Outcomes
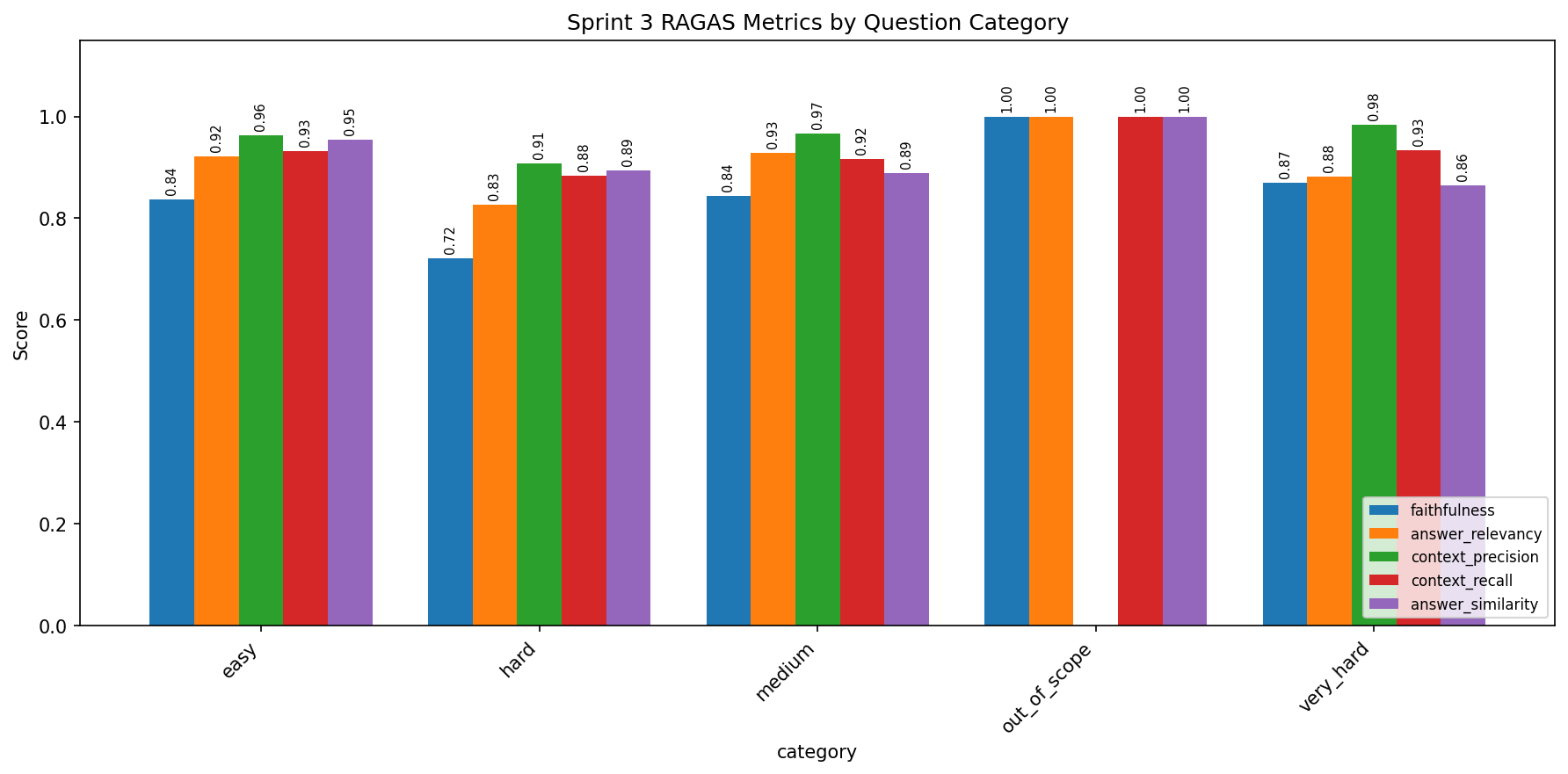
Scores by Difficulty Category
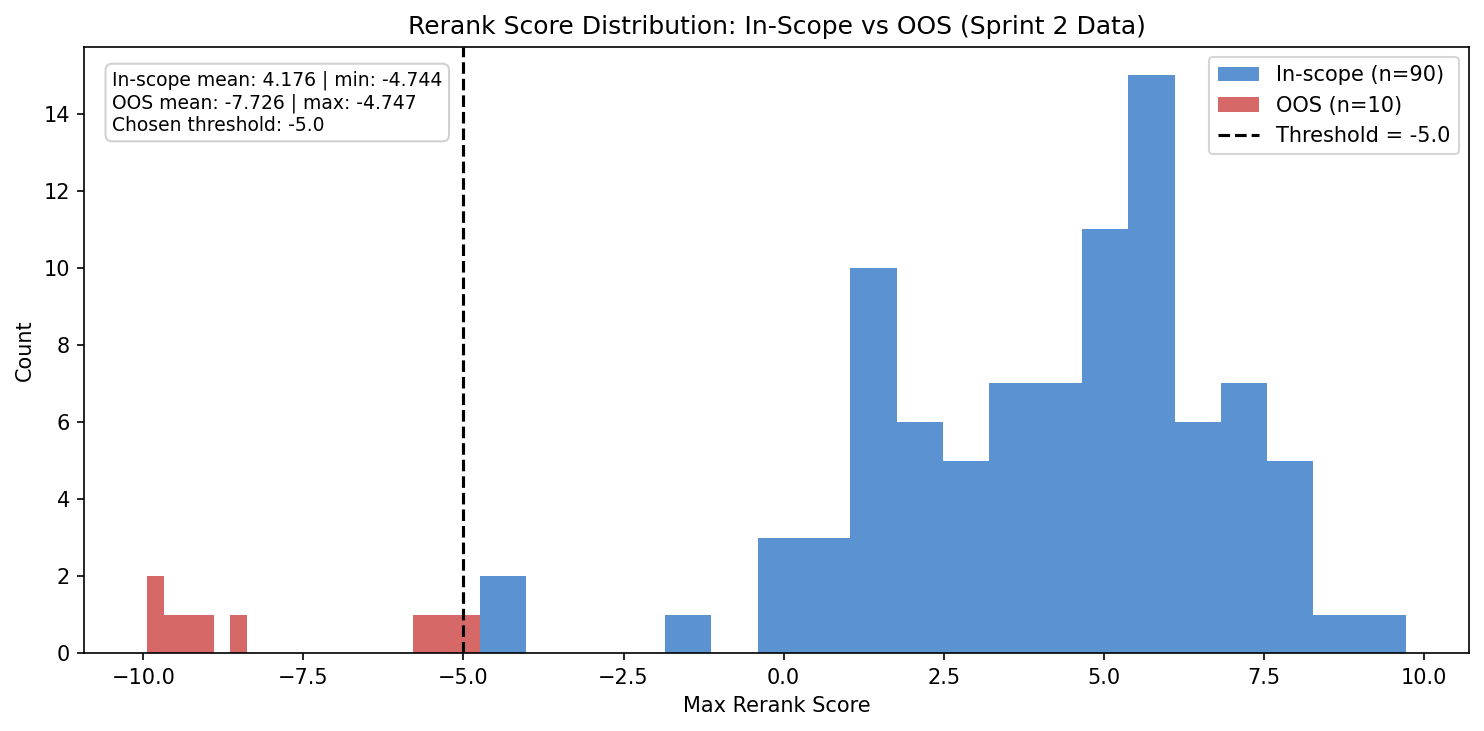
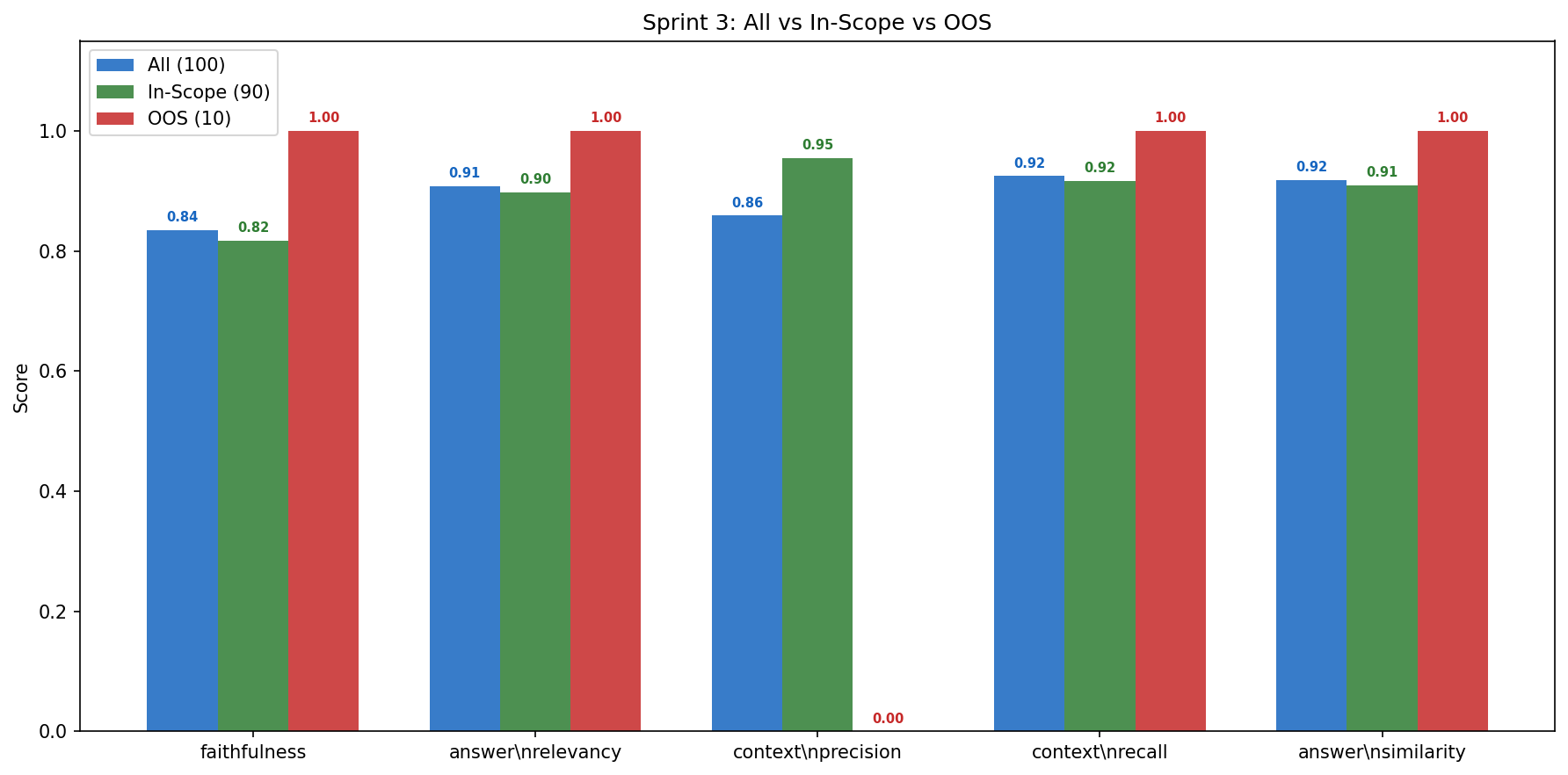
In-Scope vs Out-of-Scope
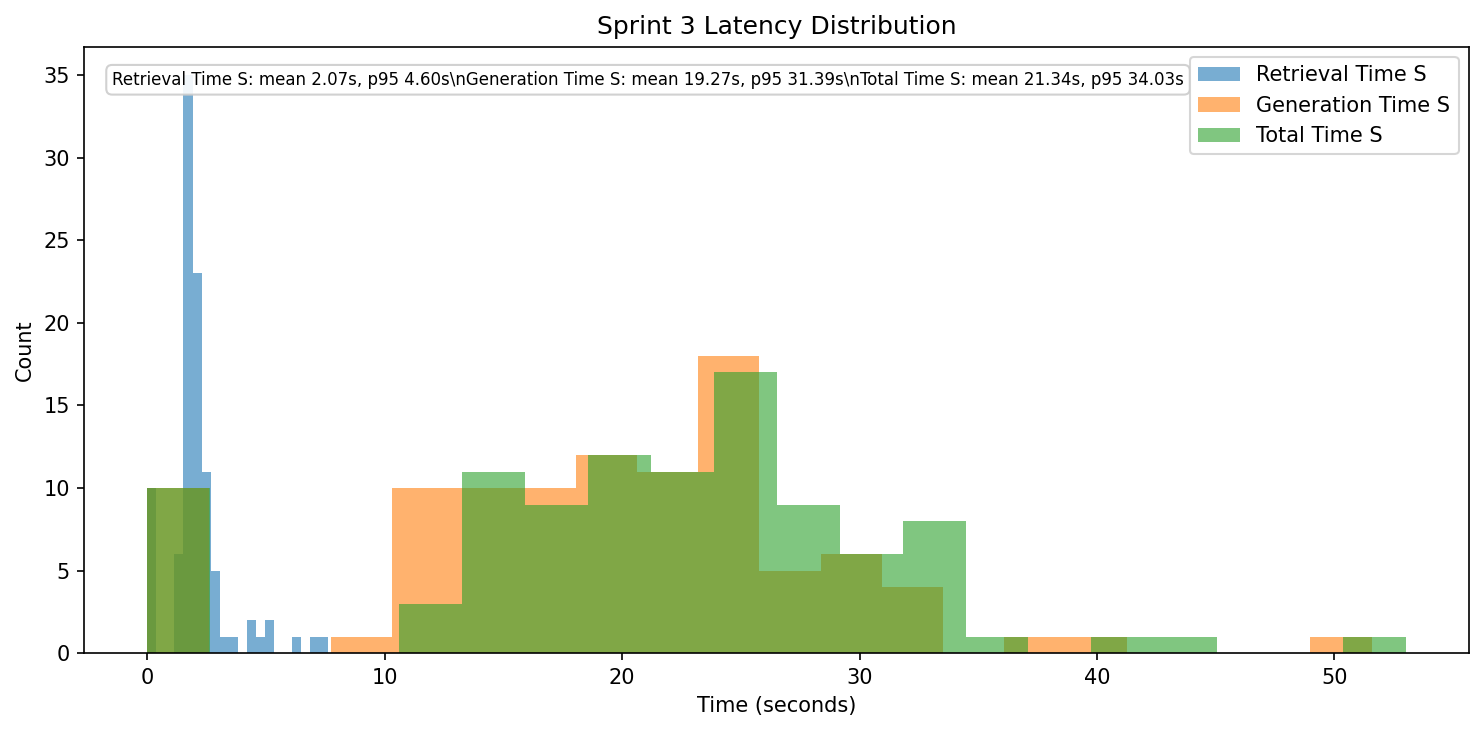
Latency Distribution
OOS Threshold Calibration